第 1 章 机器学习基础
首先简单介绍一下机器学习(Machine Learning,ML)和深度学习(Deep Learning,DL)的基本概念。机器学习,顾名思义,机器具备有学习的能力。具体来讲,机器学习就是让机器具备找一个函数的能力。机器具备找函数的能力以后,它可以做很多事。比如语音识别,机器听一段声音,产生这段声音对应的文字。我们需要的是一个函数,该函数的输入是声音信号,输出是这段声音信号的内容。这个函数显然非常复杂,人类难以把它写出来,因此想通过机器的力量把这个函数自动找出来。还有好多的任务需要找一个很复杂的函数,以图像识别为例,图像识别函数的输入是一张图片,输出是这个图片里面的内容。AlphaGo 也可以看作是一个函数,机器下围棋需要的就是一个函数,该函数的输入是棋盘上黑子跟白子的位置,输出是机器下一步应该落子的位置。
随着要找的函数不同,机器学习有不同的类别。假设要找的函数的输出是一个数值,一个标量(scalar),这种机器学习的任务称为回归。举个回归的例子,假设机器要预测未来某一个时间的 PM2.5 的数值。机器要找一个函数
除了回归以外,另一个常见的任务是分类(classification)。分类任务要让机器做选择题。人类先准备好一些选项,这些选项称为类别(class),现在要找的函数的输出就是从设定好的选项里面选择一个当作输出,该任务称为分类。举个例子,每个人都有邮箱账户,邮箱账户里面有一个函数,该函数可以检测一封邮件是否为垃圾邮件。分类不一定只有两个选项,也可以有多个选项。
AlphaGo 也是一个分类的问题,如果让机器下围棋,做一个 AlphaGo,给出的选项与棋盘的位置有关。棋盘上有
在机器学习领域里面,除了回归跟分类以外,还有结构化学习(structured learning)。机器不只是要做选择题或输出一个数字,而是产生一个有结构的物体,比如让机器画一张图,写一篇文章。这种叫机器产生有结构的东西的问题称为结构化学习。
1.1 案例学习
以视频的点击次数预测为例介绍下机器学习的运作过程。假设有人想要通过视频平台赚钱,他会在意频道有没有流量,这样他才会知道他的获利。假设后台可以看到很多相关的信息,比如:每天点赞的人数、订阅人数、观看次数。根据一个频道过往所有的信息可以预测明天的观看次数。找一个函数,该函数的输入是后台的信息,输出是隔天这个频道会有的总观看的次数.
机器学习找函数的过程,分成 3 个步骤。第一个步骤是写出一个带有未知参数的函数
其中,
第 2个步骤是定义损失(loss),损失也是一个函数。这个函数的输入是模型里面的参数,模型是

图 1.1 2017 年 1 月 1 日到 2020 年 12 月 31 日的观看次数
把 2017 年 1 月 1 日的观看次数,代入这一个函数里面
可以判断
我们不是只能用 1 月 1 日,来预测 1 月 2 日的值,可以用 1 月 2 日的值,来预测 1 月 3日的值。根据 1 月 2 日的观看次数,预测的 1 月 3 日的观看次数的,值是 5400。接下来计算5400 跟跟标签(7500)之间的差距,低估了这个频道。在 1 月 3 日的时候的观看次数,才可以算出:
我们可以算过这 3 年来,每一天的预测的误差,这 3 年来每一天的误差,通通都可以算出来,每一天的误差都可以得到
其中,
估测的值跟实际的值之间的差距,其实有不同的计算方法,计算
如果算
有一些任务中
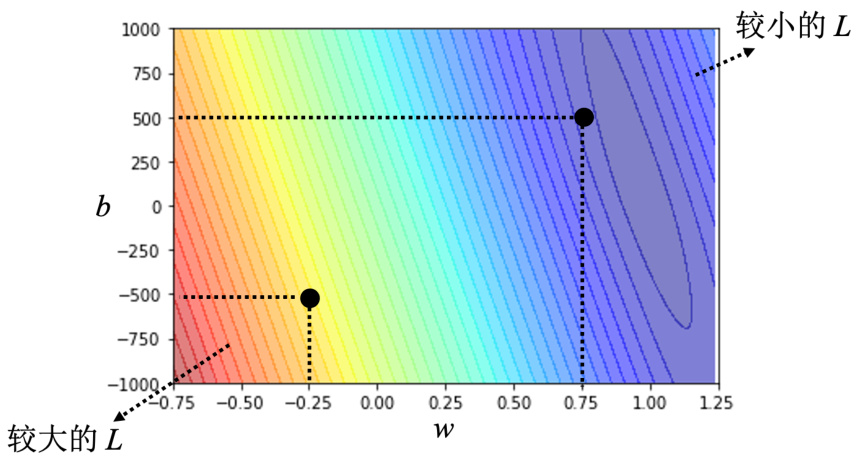
图 1.2 误差表面
接下来进入机器学习的第 3 步:解一个最优化的问题。找一个
• 第一件事情是这个地方的斜率,斜率大步伐就跨大一点,斜率小步伐就跨小一点。• 另外,学习率(learning rate)
Q: 为什么损失可以是负的?
A: 损失函数是自己定义的,在刚才定义里面,损失就是估测的值跟正确的值的绝对值。如果根据刚才损失的定义,它不可能是负的。但是损失函数是自己决定的,比如设置一个损失函数为绝对值再减 100,其可能就有负的。这个曲线并不是一个真实的损失,并不是一个真实任务的误差表面。因此这个损失的曲线可以是任何形状。
把
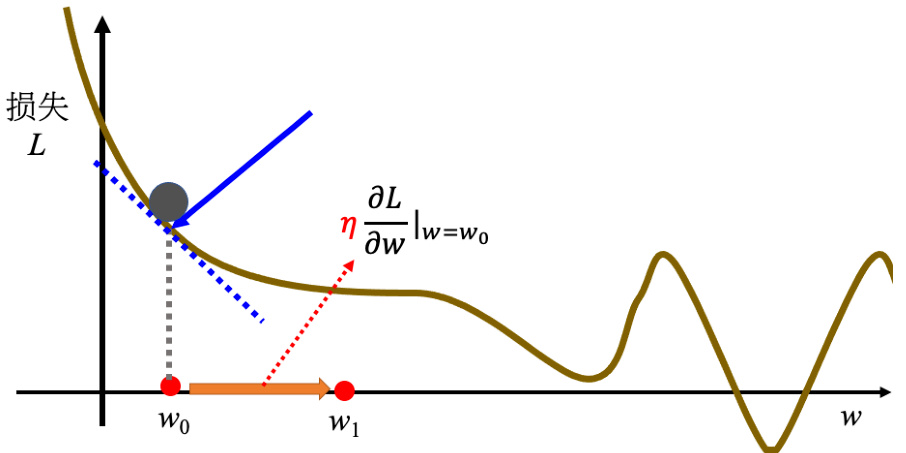
图 1.3 优化过程
接下来反复进行刚才的操作,计算一下
• 第一种情况是一开始会设定说,在调整参数的时候,在计算微分的时候,最多计算几次。上限可能会设为 100 万次,参数更新 100 万次后,就不再更新了,更新次数也是一个超参数。
• 还有另外一种理想上的,停下来的可能是,当不断调整参数,调整到一个地方,它的微分的值就是这一项,算出来正好是 0 的时候,如果这一项正好算出来是 0,0 乘上学习率
梯度下降有一个很大的问题,没有找到真正最好的解,没有找到可以让损失最小的
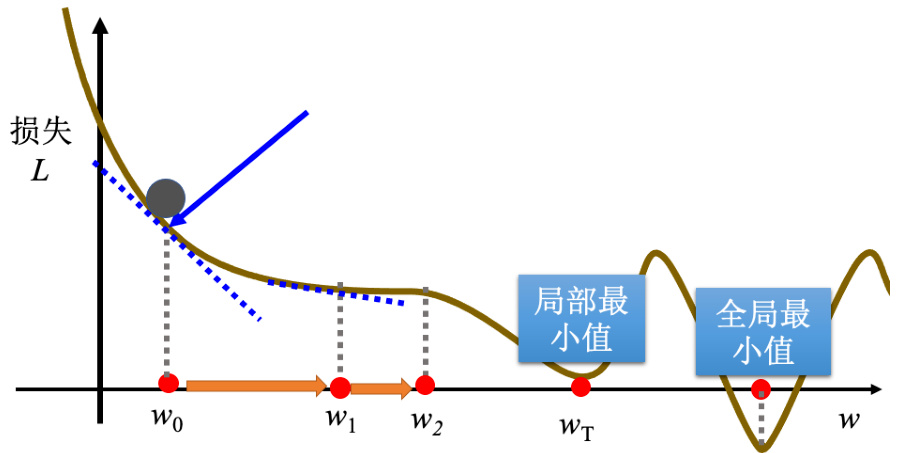
图 1.4 局部最小值
所以常常可能会听到有人讲到梯度下降不是个好方法,这个方法会有局部最小值的问题,无法真的找到全局最小值。事实上局部最小值是一个假问题,在做梯度下降的时候,真正面对的难题不是局部最小值。有两个参数的情况下使用梯度下降,其实跟刚才一个参数没有什么不同。如果一个参数没有问题的话,可以很快的推广到两个参数。
假设有两个参数,随机初始值为
计算完后更新
上微分的结果得到
在深度学习框架里面,比如 PyTorch 里面,算微分都是程序自动帮计算的。就是反复同样的步骤,就不断的更新
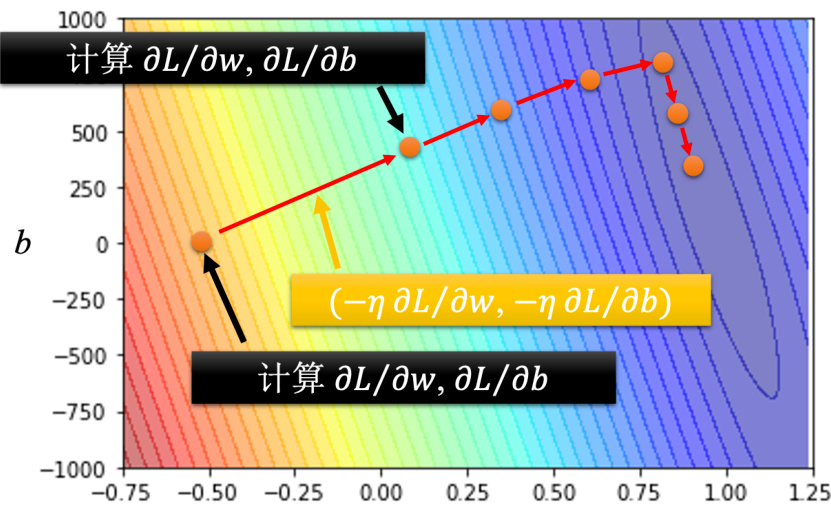
图 1.5 梯度下降优化的过程
1.2 线性模型
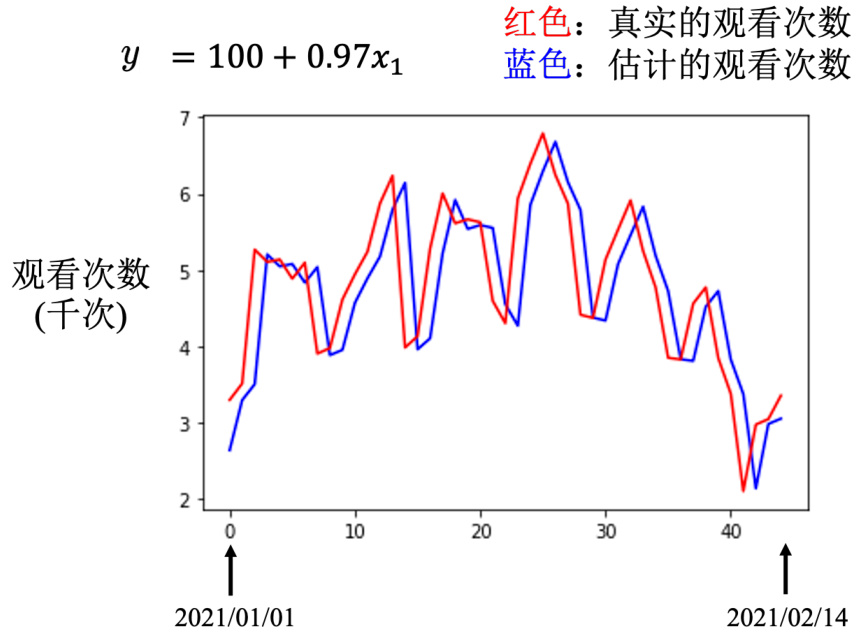
图 1.6 预估曲线图
一开始,对问题完全不理解的时候,胡乱写一个
并没有做得特别好。接下来我们观察了真实的数据以后,得到一个结论是,每隔 7 天有一个循环。所以要把前 7 天的观看人次都列入考虑,写了一个新的模型
其中
表 1.1
| b | wi 米 | W2 | W3 | W4 * | w5 * | W6 * | W* * |
| 50 | 0.79 | -0.31 | 0.12 | -0.01 | -0.10 | 0.30 | 0.18 |
机器的逻辑是前一天跟要预测的隔天的数值的关系很大,所以
28 天是一个月,考虑前一个月每一天的观看人次,去预测隔天的观看人次,训练数据上是 330。在 2021 年的数据上,损失是 460,看起来又更好一点。如果考虑 56 天,即
在训练数据上损失是 320,在没看过的数据上损失还是 460。考虑更多天没有办法再更降低损失了。看来考虑天数这件事,也许已经到了一个极限。这些模型都是把输入的特征
1.2.1 分段线性曲线
线性模型也许过于简单,
所以需要写一个更复杂的、更有灵活性的、有未知参数的函数。红色的曲线可以看作是一个常数再加上一群 Hard Sigmoid 函数。Hard Sigmoid 函数的特性是当输入的值,当 x 轴的值小于某一个阈值(某个定值)的时候,大于另外一个定值阈值的时候,中间有一个斜坡。所以它是先水平的,再斜坡,再水平的。所以红色的线可以看作是一个常数项加一大堆的蓝色函数(Hard Sigmoid)。常数项设成红色的线跟
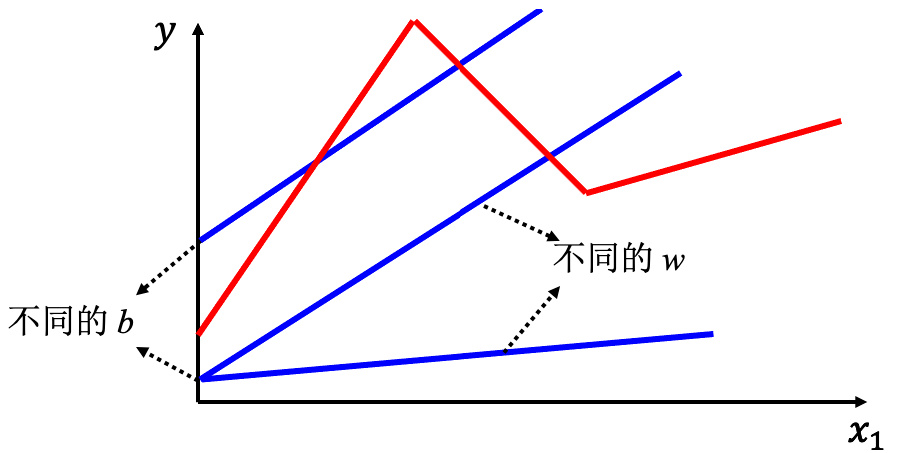
图 1.7 线性模型的局限性
所以红色线,即分段线性曲线(piecewise linear curve)可以看作是一个常数,再加上一堆蓝色的函数。分段线性曲线可以用常数项加一大堆的蓝色函数组合出来,只是用的蓝色函数不一定一样。要有很多不同的蓝色函数,加上一个常数以后就可以组出这些分段线性曲线。如果分段线性曲线越复杂,转折的点越多,所需的蓝色函数就越多。
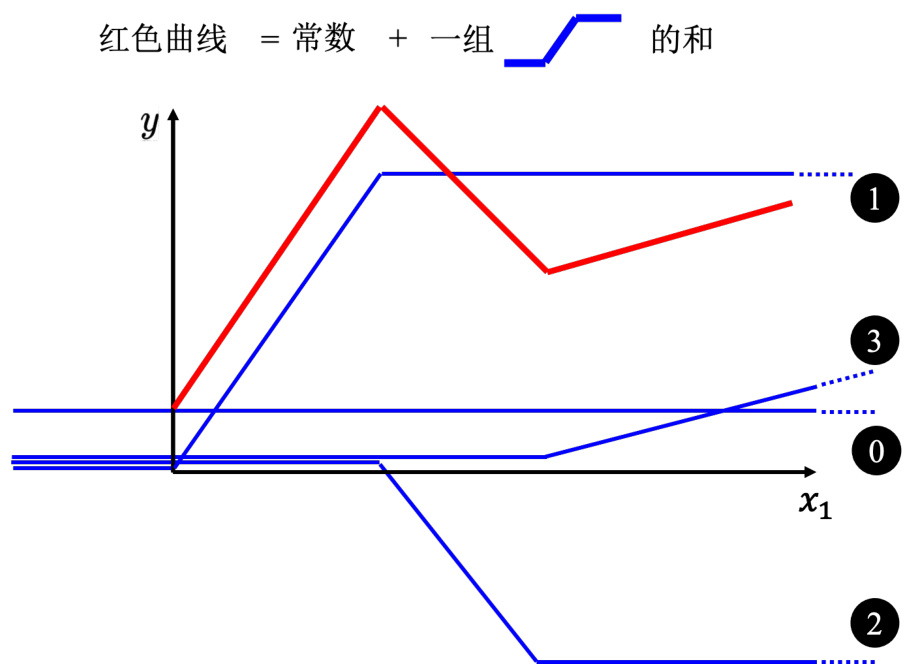
图 1.8 构建红色曲线
也许要考虑的
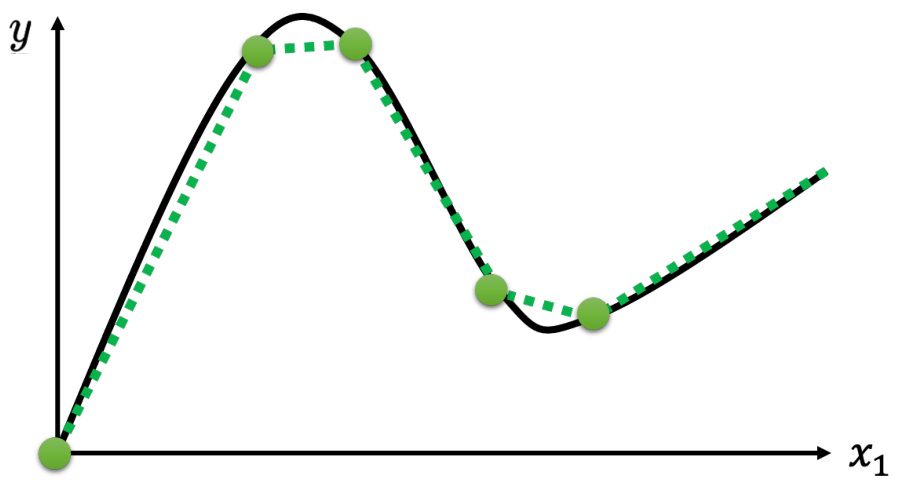
图 1.9 分段曲线可以逼近任何连续曲线
假设
其横轴输入是
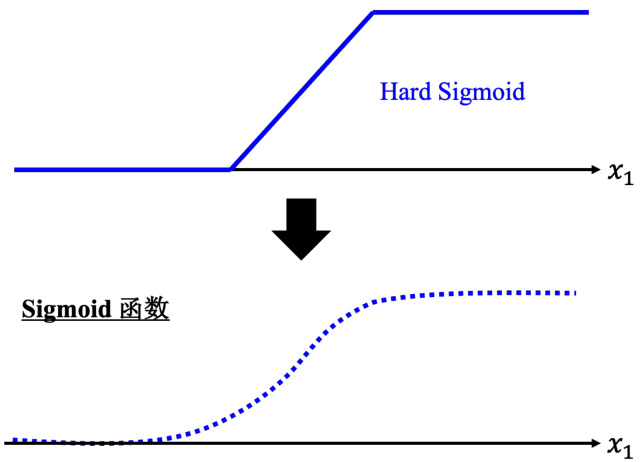
图 1.10 使用 Sigmoid 逼近 Hard Sigmoid
如果
所以可以用这样子的一个函数逼近这一个蓝色的函数,即 Sigmoid 函数,Sigmoid 函数就是 S 型的函数。因为它长得是有点像是 S 型,所以叫它 Sigmoid 函数。
为了简洁,去掉了指数的部分,蓝色函数的表达式为
所以可以用 Sigmoid 函数逼近 Hard Sigmoid 函数。
调整这里的
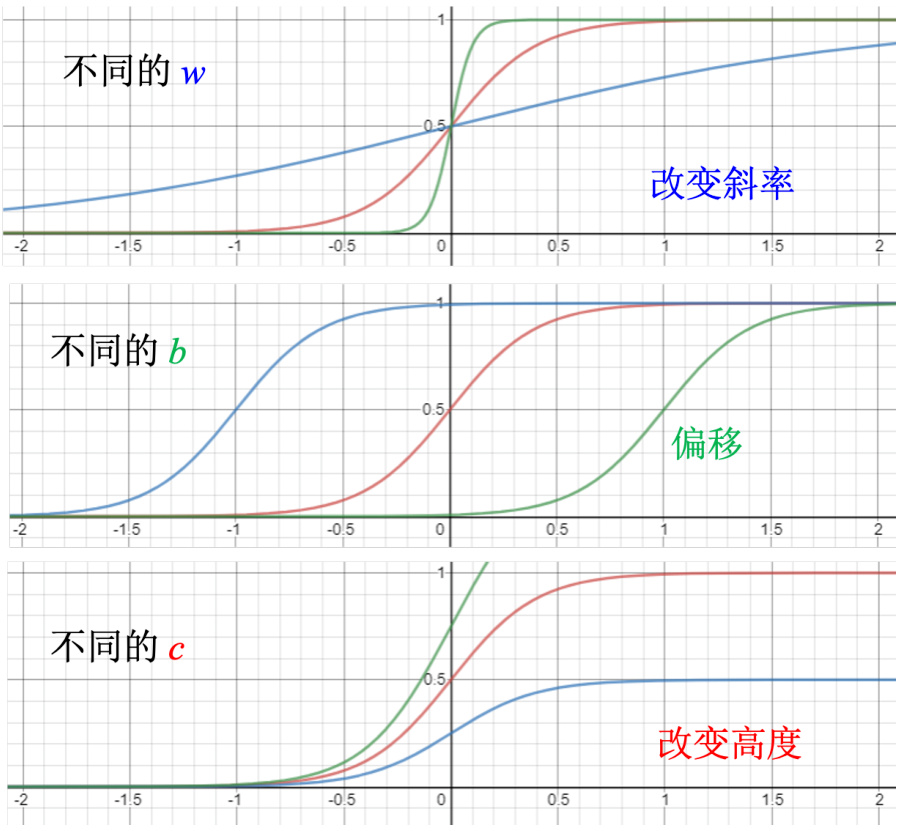
图 1.11 调整参数,制造不同的 Sigmoid 函数
如图 1.12 所示,红色这条线就是 0 加
所以这边每一个式子都代表了一个不同蓝色的函数,求和就是把不同的蓝色的函数相加,再加一个常数
此外,我们可以不只用一个特征
直观来讲,先考虑一下
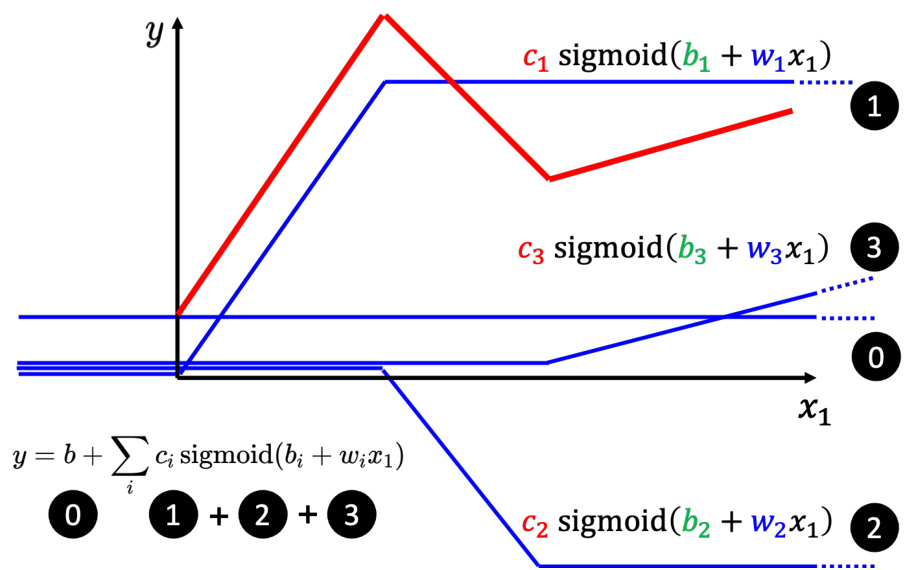
图 1.12 使用 Hard Sigmoid 来合成红色
我们可以用矩阵跟向量相乘的方法,写一个比较简洁的写法。
将其改成线性代数比较常用的表示方式为
蓝框里面的括号里面做的如式 (1.21) 所示,
因此蓝色虚线框里面做的事情,是从
上面这个比较有灵活性的函数,如果用线性代数来表示,即
接下来,如图 1.15 所示,

图 1.13 构建更有灵活性的函数
Q: 优化是找一个可以让损失最小的参数,是否可以穷举所有可能的未知参数的值?A:只有
Q:刚才的例子里面有 3 个 Sigmoid,为什么是 3 个,能不能 4 个或更多?
A:Sigmoid 的数量是由自己决定的,而且 Sigmoid 的数量越多,可以产生出来的分段线性函数就越复杂。Sigmoid 越多可以产生有越多段线的分段线性函数,可以逼近越复杂的函数。Sigmoid 的数量也是一个超参数。
接下来要定义损失。之前是
先给定
接下来下一步就是优化
要找到
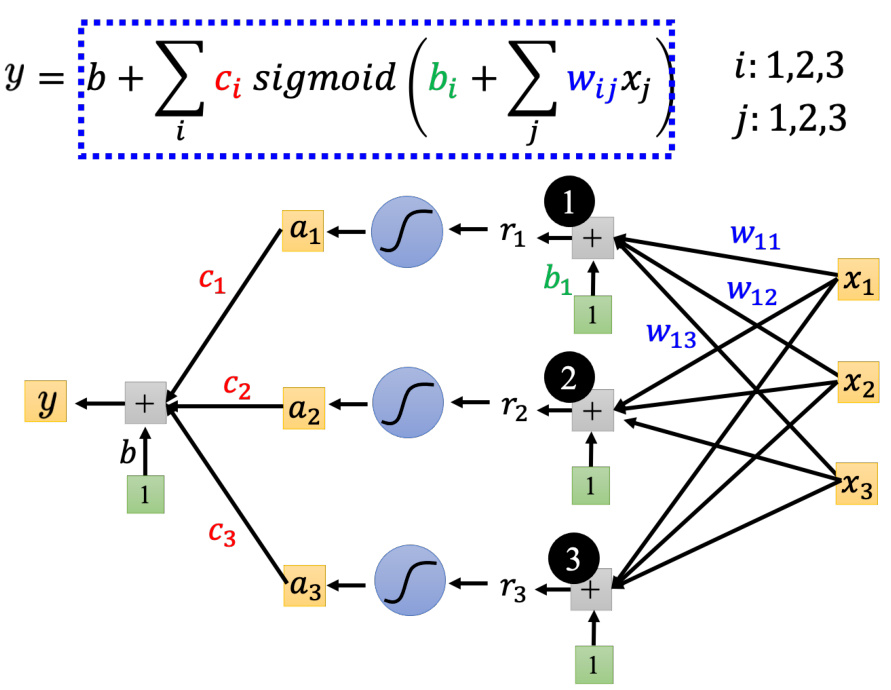
图 1.14 比较有灵活性函数的计算过程
的数值
假设有 1000 个参数,这个向量的长度就是 1000,这个向量也称为梯度,
假设参数有 1000 个,
含有未知参数的函数
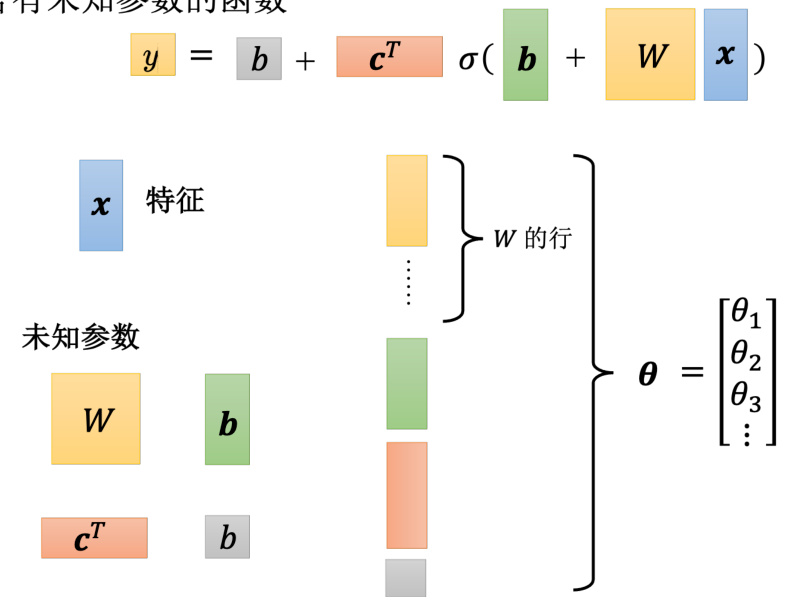
图 1.15 未知参数“拼”成一个向量
图 1.16 使用梯度下降更新参数
做。或者计算出梯度为 0 向量,导致无法再更新参数为止,不过在实现上几乎不太可能梯度为 0,通常会停下来就是我们不想做了。
)(随机)选取初始值
·计算梯度
·计算梯度
·计算梯度
但实现上有个细节的问题,实际使用梯度下降的时候,如图 1.17 所示,会把
所以并不是拿
更新跟回合的差别,举个例子,假设有 10000 笔数据,即
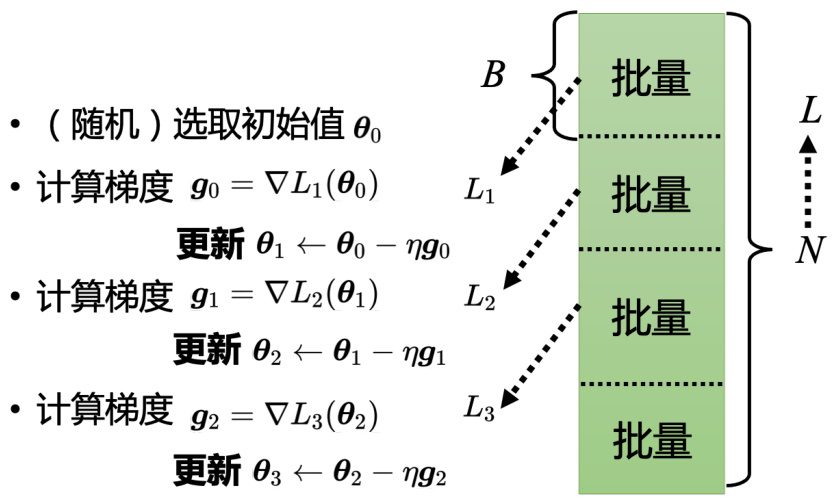
图 1.17 分批量进行梯度下降
更新了参数 1000 次了。
第 2 个例子,假设有 1000 个数据,批量大小(batch size)设 100,批量大小和 Sigmoid的个数都是超参数。1000 个样本,批量大小设 100,1 个回合总共更新 10 次参数。所以做了一个回合的训练其实不知道它更新了几次参数,有可能 1000 次,也有可能 10 次,取决于它的批量大小有多大。
1.2.2 模型变形
其实还可以对模型做更多的变形,不一定要把 Hard Sigmoid 换成 Soft Sigmoid。HardSigmoid 可以看作是两个修正线性单元(Rectified Linear Unit,ReLU)的加总,ReLU 的图像有一个水平的线,走到某个地方有一个转折的点,变成一个斜坡,其对应的公式为
如图 1.19 所示,2 个 ReLU 才能够合成一个 Hard Sigmoid。要合成
当然还有其他常见的激活函数,但 Sigmoid 跟 ReLU 是最常见的激活函数,接下来的实验都选择用了 ReLU,显然 ReLU 比较好,实验结果如图 1.20 所示。如果是线性模型,考虑56 天,训练数据上面的损失是 320,没看过的数据 2021 年数据是 460。连续使用 10 个 ReLU作为模型,跟用线性模型的结果是差不多的,
但连续使用 100 个 ReLU 作为模型,结果就有显著差别了,100 个 ReLU 在训练数据上的损失就可以从 320 降到 280,有 100 个 ReLU 就可以制造比较复杂的曲线,本来线性就是一直线,但 100 个 ReLU 就可以产生 100 个折线的函数,在测试数据上也好了一些. 接下来
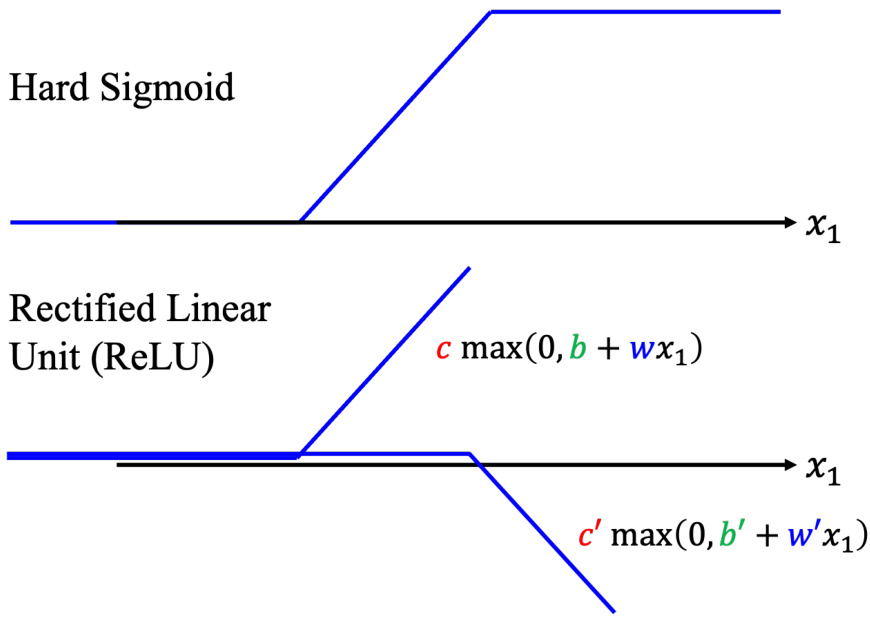
图 1.18 ReLU 函数
激活函数
图 1.19 激活函数
使用 1000 个 ReLU 作为模型,在训练数据上损失更低了一些,但是在没看过的数据上,损失没有变化。
接下来可以继续改模型,如图 1.21 所示,从
每次都加 100 个 ReLU,输入特征,就是 56 天前的数据。如图 1.22 所示,如果做两次,损失降低很多,280 降到 180。如果做 3 次,损失从 180 降到 140,通过 3 次 ReLU,从 280降到 140,在训练数据上,在没看过的数据上,从 430 降到了 380。
通过 3 次 ReLU 的实验结果如图 1.23 所示。横轴就是时间,纵轴是观看次数。红色的线是真实的数据,蓝色的线是预测出来的数据在这种低点的地方啊,看红色的数据是每隔一段时间,就会有两天的低点,在低点的地方,机器的预测还算是蛮准确的,机器高估了真实的观看人次,尤其是在红圈标注的这一天,这一天有一个很明显的低谷,但是机器没有预测到这一天有明显的低谷,它是晚一天才预测出低谷。这天最低点就是除夕。但机器只知道看前 56 天的值,来预测下一天会发生什么事,所以它不知道那一天是除夕。
| 线性 | 10ReLU | 100ReLU | 1000ReLU | |
| 2017-2020 | 320 | 320 | 280 | 270 |
| 2021 | 460 | 450 | 430 | 430 |
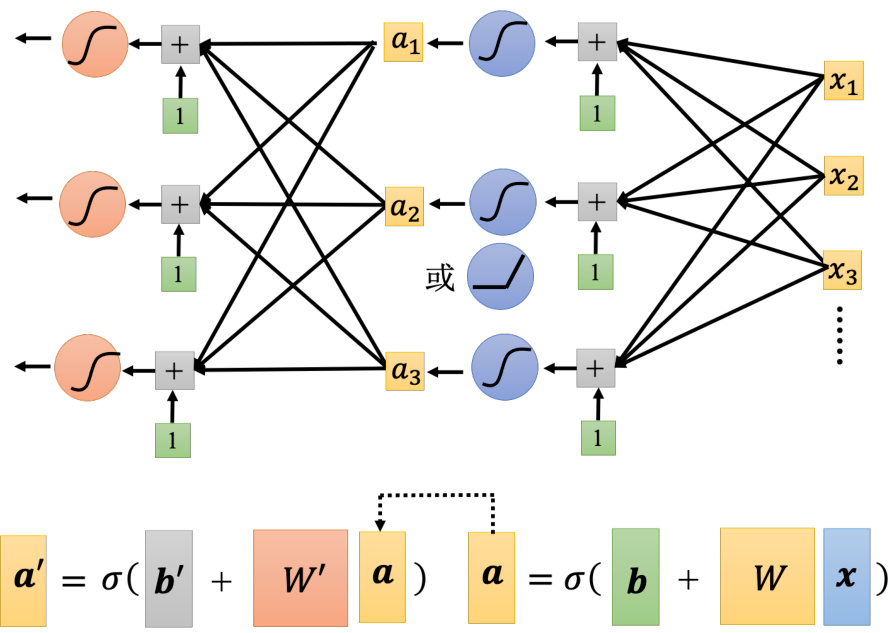
图 1.20 激活函数实验结果
图 1.21 改进模型
图 1.22 使用 ReLU 的实验结果
如图 1.24 所示,Sigmoid 或 ReLU 称为神经元(neuron),很多的神经元称为神经网络(neural network)。人脑中就是有很多神经元,很多神经元串起来就是一个神经网络,跟人脑是一样的。人工智能就是在模拟人脑。神经网络不是新的技术,80、90 年代就已经用过了,后来为了要重振神经网络的雄风,所以需要新的名字。每一排称为一层,称为隐藏层(hiddenlayer),很多的隐藏层就“深”,这套技术称为深度学习。
所以人们把神经网络越叠越多越叠越深,2012 年的 AlexNet 有 8 层它的错误率是
刚才只做到 3 层,应该要做得更深,现在网络都是叠几百层的,深度学习就要做更深。但4 层在训练数据上,损失是 100,在 2021 年的数据上,损失是 440。在训练数据上,3 层比 4层差,但是在没看过的数据上,4 层比较差,3 层比较好,如图 1.25 所示。在训练数据和测试数据上的结果是不一致的,这种情况称为过拟合(overfitting)。
| 1层 | 2层 | 3层 | 4层 | |
| 2017 -2020 | 280 | 180 | 140 | 100 |
| 2021 | 430 | 390 | 380 | 440 |
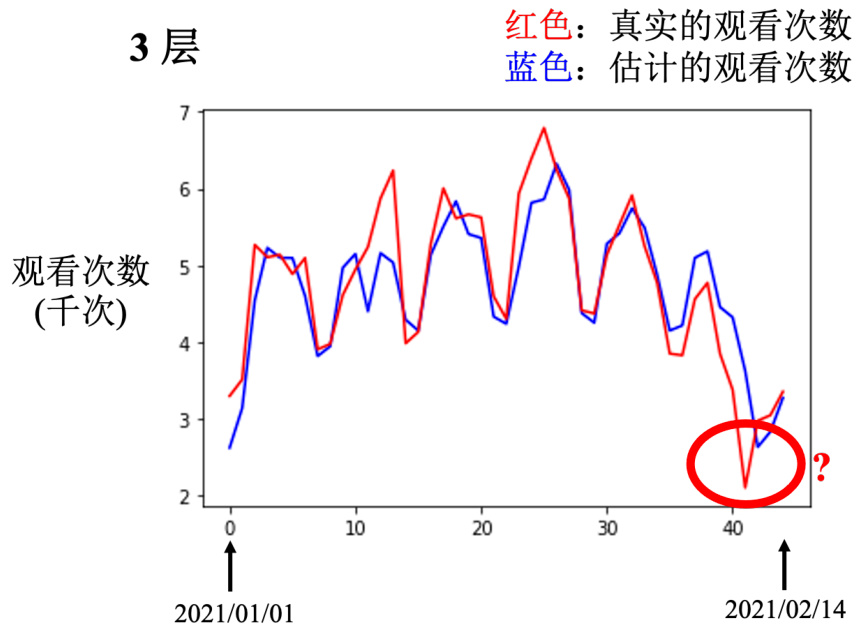
图 1.23 使用 3 次 ReLU 的实验结果
但是做到目前为止,还没有真的发挥这个模型的力量,2021 年的数据到 2 月 14 日之前的数据是已知的。要预测未知的数据,选 3 层的网络还是 4 层的网络呢?假设今天是 2 月 26日,今天的观看次数是未知的,如果用已经训练出来的神经网络预测今天的观看次数。要选3 层的,虽然 4 层在训练数据上的结果比较好,但在测试数据的结果更重要。应该选一个在训练的时候,测试的数据上表现会好的模型,所以应该选 3 层的网络。深度学习的训练会用到反向传播(BackPropagation,BP),其实它就是比较有效率、算梯度的方法。
1.2.3 机器学习框架
我们会有一堆训练的数据以及测试数据如式 (1.30) 所示,测试集就是只有
训练集就要拿来训练模型,训练的过程是 3 个步骤。
先写出一个有未知数
的函数, 代表一个模型里面所有的未知参数。 的意思就是函数叫 ,输入的特征为 ; 定义损失,损失是一个函数,其输入就是一组参数,去判断这一组参数的好坏;
解一个优化的问题,找一个
,该 可以让损失的值越小越好。让损失的值最小的 为 ,即
有了
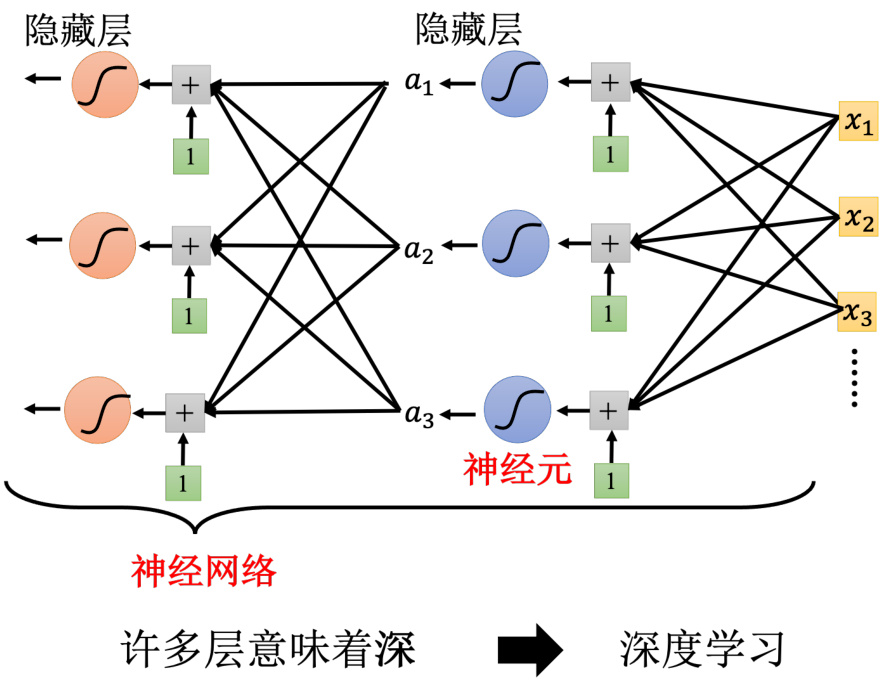
图 1.24 深度学习的结构
图 1.25 模型有过拟合问题
| 1层 | 2层 | 3层 | 4层 | |
| 2017-2020 | 280 | 180 | 140 | 100 |
| 2021 | 430 | 390 | 380 | 440 |